
Exercise 8: Bellmans equations and exact planning#
Note
This page contains background information which may be useful in future exercises or projects. You can download this weeks exercise instructions from here:
You are encouraged to prepare the homework problems 1, 2 (indicated by a hand in the PDF file) at home and present your solution during the exercise session.
To get the newest version of the course material, please see Making sure your files are up to date
Markov decision processes#
The Markov Decision Process (MDP) is a mathematical description of the problem solved by most reinforcement learning methods.
It will be represented as the class MDP and will stand in the same relationship to methods such as value iteration as the DPModel play to the dynamical programming method.
Let’s look at the MDP for the frozen-lake gridworld environment. It looks as follows:
# BookGridEnvironment
from irlc.gridworld.gridworld_environments import FrozenLake
from irlc import train, Agent, interactive
env = FrozenLake(render_mode="human") # Pass render_mode='human' for visualization.
env, agent = interactive(env, Agent(env)) # Make th
env.reset() # You always need to call reset
env.plot() # Plot the environment.
env.close()
(Source code, png, hires.png, pdf)
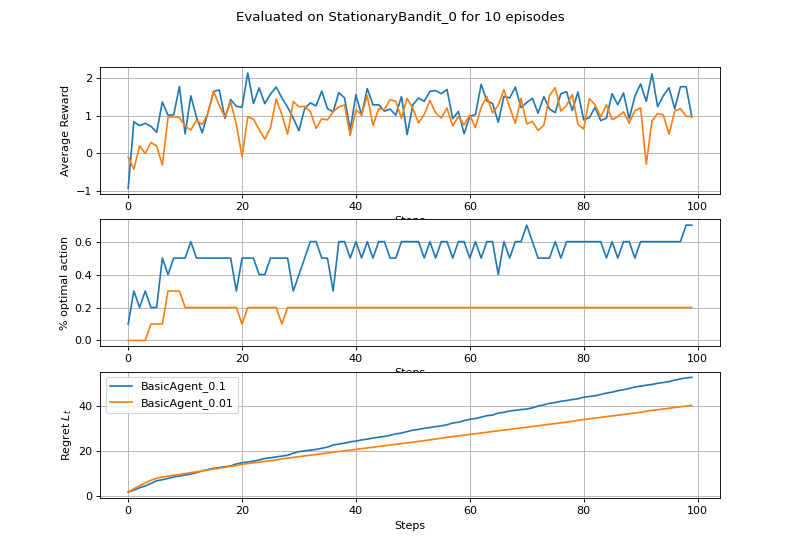{kind=link}
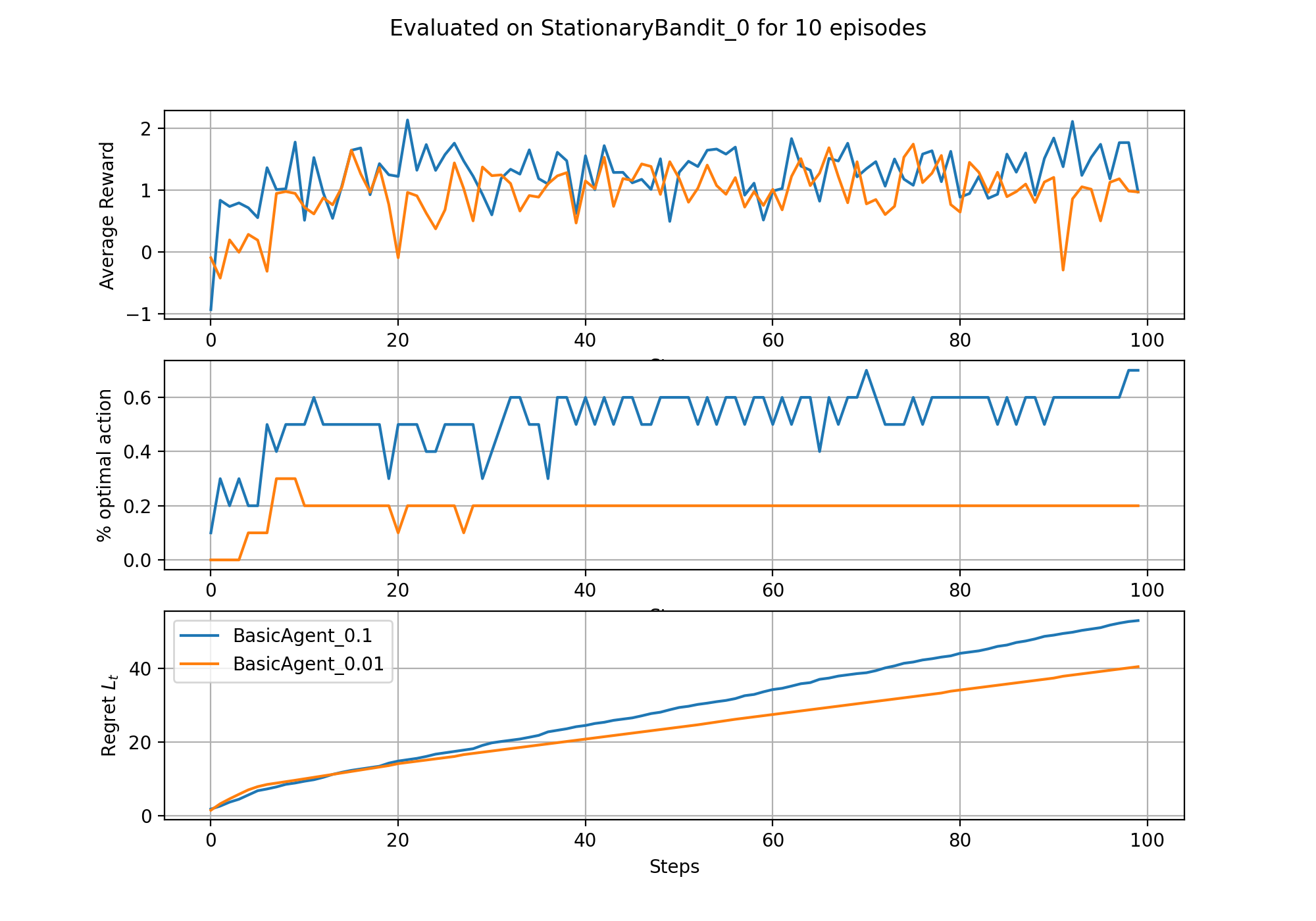{kind=link}
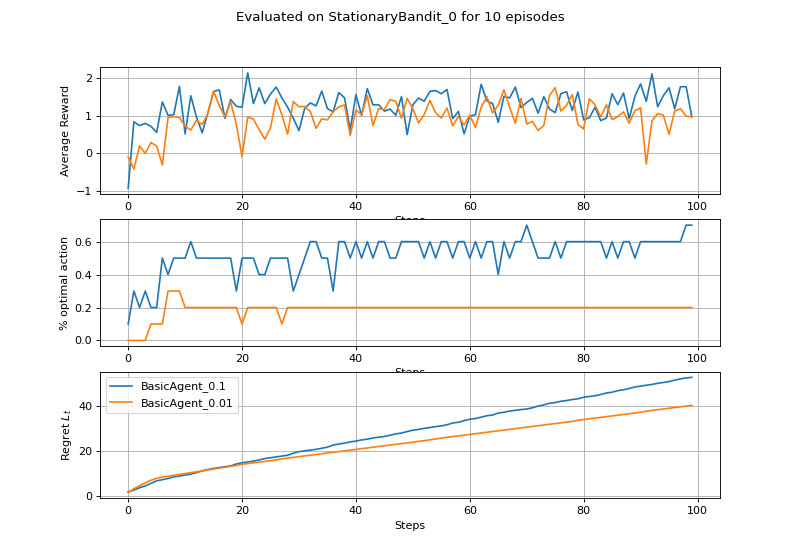
We can instantiate the MDP class directly, or extract if from the gridworld environment as env.mdp. A couple of examples:
This code plots the initial state, all non-terminal states, and the actions in the initial state:
>>> from irlc.gridworld.gridworld_environments import FrozenLake
>>> mdp = FrozenLake().mdp # Get the MDP.
>>> mdp.initial_state # States are tuples (x, y)
(0, 3)
>>> mdp.A(mdp.initial_state) # Get all actions in the initial state
(0, 1, 2, 3)
Warning
The actions available in the different states are not the same in the gridworld environment. Specifically, the winning (goal) state only has a single action, which takes the environment to the terminal state. Let’s take a look:
>>> from irlc.gridworld.gridworld_environments import FrozenLake
>>> mdp = FrozenLake().mdp
>>> mdp.A( (0, 3) ) # Actions in the starting state
(0, 1, 2, 3)
>>> mdp.A( (0, 0) ) # Actions the bottom-left state
(0,)
Transitions probabilities#
The transition probabilities:
Are represented as a function Psr() that returns a dictionary of the form {(s1, r1): p1, (s2, r2): p2, ...}, compare to irlc.ex02.dp_model.DPModel.Pw(). An example:
>>> from irlc.gridworld.gridworld_environments import FrozenLake
>>> mdp = FrozenLake().mdp
>>> transitions = mdp.Psr(mdp.initial_state, 0)
>>> for (sp, r), p in transitions.items():
... print(f"P(s'={sp}, r={r} | s={mdp.initial_state}, a=0) = {p}")
...
P(s'=(0, 3), r=0 | s=(0, 3), a=0) = 0.6666666666666667
P(s'=(1, 3), r=0 | s=(0, 3), a=0) = 0.3333333333333333
Note
It is easy to miss, but (Sutton and Barto [SB18]) distinguish between
The set of all states, \(\mathcal{S}^+\) corresponding to
states()The set of all non non-terminal states \(\mathcal{S}\) corresponding to
nonterminal_states()
The value-function for a terminal states. Both the policy, value-function, action-value function and transition probabilities \(P(s',r|s,a)\) are only defined in non-terminal states, and it is a common mistake in reinforcement learning to update or evaluate them in terminal states. Let’s take a look:
>>> from irlc.gridworld.gridworld_environments import FrozenLake
>>> mdp = FrozenLake().mdp # Get the MDP.
>>> mdp.nonterminal_states
[(0, 1), (1, 2), (2, 1), (0, 0), (3, 1), (1, 1), (0, 3), (2, 0), (3, 0), (2, 3), (0, 2), (3, 3), (2, 2), (1, 0), (3, 2), (1, 3)]
>>> mdp.states
[(0, 1), (1, 2), (2, 1), (0, 0), (3, 1), (1, 1), (0, 3), (2, 0), 'Terminal state', (3, 0), (2, 3), (0, 2), (3, 3), (2, 2), (1, 0), (3, 2), (1, 3)]
>>> terminal_states = [s for s in mdp.states if s not in mdp.nonterminal_states]
>>> terminal_states
['Terminal state']
Building a MDP#
Building your own MDP is easy. Let’s try to implement a MDP corresponding to a small gridworld example (see (Sutton and Barto [SB18]), Example 4.1)
# small_gridworld.py
UP,RIGHT, DOWN, LEFT = 0, 1, 2, 3
class SmallGridworldMDP(MDP):
def __init__(self, rows=4, cols=4):
self.rows, self.cols = rows, cols # Number of rows, columns.
super().__init__(initial_state=(rows//2, cols//2) ) # Initial state is in the middle of the board.
def A(self, state):
return [UP, DOWN, RIGHT, LEFT] # All four directions available.
def Psr(self, state, action):
row, col = state # state is in the format state = (row, col)
if action == UP: row -= 1
if action == DOWN: row += 1
if action == LEFT: col += 1
if action == RIGHT: col -= 1
col = min(self.cols-1, max(col, 0)) # Check boundary conditions.
row = min(self.rows-1, max(row, 0))
reward = -1 # Always get a reward of -1
next_state = (row, col)
# Note that P(next_state, reward | state, action) = 1 because environment is deterministic
return {(next_state, reward): 1}
def is_terminal(self, state):
row, col = state
return (row == 0 and col == 0) or (row == self.rows-1 and col == self.cols-1)
Note that:
The states are tuples of row, col coordinates
(i,j)Each state has 4 actions, so the action-space function
A(state)simply returns the list[0, 1, 2, 3]The
is_terminalfunction determines if we are in a corner (\((0,0)\) or \((3,3)\))The transition probabilities are deterministic. So the dictionary it returns has a single key
(next_state, reward)and value of1
Classes and functions#
- class irlc.ex08.mdp.MDP(initial_state=None, verbose=False)[source]#
Bases:
objectThis class represents a Markov Decision Process. It defines three main components: - The actions available in a given state \(A(s)\) - The transition probabilities \(p(s', r | s, a)\) - A terminal check to determine if a state \(s\) is terminal - A way to specify the initial state:
As a single state the MDP always begins in (most common)
As a general distribution \(p(s_0)\).
In addition to this it allows you to access either - The set of all states (including terminal states) as
mdp.states- The set of all non-terminal states asmdp.non_terminal_statesNote
The
statesandnon_termianl_statesare computed lazily. This means that if you don’t access them, they won’t use memory. This allows you to specify MDPs with an infinite number of states without running out of memory.- __init__(initial_state=None, verbose=False)[source]#
Initialize the MDP. In the case where
initial_stateis set to a value \(s_0\), the initial state distribution will be\[p(s_0) = 1\]- Parameters:
initial_state – An optional initial state.
verbose – If
True, the class will print out debug information (useful for very large MDPs)
- is_terminal(state)[source]#
Determines if a state is terminal (i.e., the environment/model is complete). In (SB18), the terminal state is written as \(s_T\).
>>> from irlc.gridworld.gridworld_environments import FrozenLake >>> mdp = FrozenLake().mdp >>> mdp.is_terminal(mdp.initial_state) # False, obviously. False
- Parameters:
state – The state \(s\) to check
- Return type:
- Returns:
Trueif the state is terminal and otherwiseFalse.
- Psr(state, action)[source]#
Represents the transition probabilities:
\[P(s', r | s, a)\]When called with state
stateand actionaction, the function returns a dictionary of the form{(s1, r1): p1, (s2, r2): p2, ...}, so thatp2is the probability of transitioning tos2(and obtaining rewardr2) given we are in statestateand take actionaction:\[P(s_2, r_2 | s,a) = p_2\]An example:
>>> from irlc.gridworld.gridworld_environments import FrozenLake >>> mdp = FrozenLake().mdp >>> transitions = mdp.Psr(mdp.initial_state, 0) # P( ... | s0, a=0) >>> for (sp, r), p in transitions.items(): ... print(f"P(s'={sp}, r={r} | s={mdp.initial_state}, a=0) = {p}") ... P(s'=(0, 3), r=0 | s=(0, 3), a=0) = 0.6666666666666667 P(s'=(1, 3), r=0 | s=(0, 3), a=0) = 0.3333333333333333
- Parameters:
state – The state to compute the transition probabilities in
action – The action to compute the transition probabilities in
- Return type:
- Returns:
A dictionary where the keys are state, reward pairs we will transition to, \(p(s', r | ...)\), and the values are their probability.
- A(state)[source]#
Returns a list of actions available in the given state:
\[A(s)\]An example to get the actions in the initial state:
>>> from irlc.gridworld.gridworld_environments import FrozenLake >>> mdp = FrozenLake().mdp >>> mdp.A(mdp.initial_state) (0, 1, 2, 3)
- Parameters:
state – State to compute the actions in \(s\)
- Return type:
- Returns:
The list of available actions \(\mathcal A(s) = \{0, 1, ..., n-1\}\)
- initial_state_distribution()[source]#
(Optional) specify the initial state distribution. Should return a dictionary of the form:
{s0: p0, s1: p1, ..., sn: pn}, in which case \(p(S_0 = s_k) = p_k\).You will typically not overwrite this function but just set the initial state. In that case the initial state distribution is deterministic:
>>> from irlc.gridworld.gridworld_environments import FrozenLake >>> mdp = FrozenLake().mdp >>> mdp.initial_state_distribution() {(0, 3): 1}
- Returns:
An initial state distribution as a dictionary, where the keys are states, and the valuse are their probability.
- property nonterminal_states#
The list of non-terminal states, i.e. \(\mathcal{S}\) in (SB18)
>>> from irlc.gridworld.gridworld_environments import FrozenLake >>> mdp = FrozenLake().mdp >>> mdp.nonterminal_states [(0, 1), (1, 2), (2, 1), (0, 0), (3, 1), (1, 1), (0, 3), (2, 0), (3, 0), (2, 3), (0, 2), (3, 3), (2, 2), (1, 0), (3, 2), (1, 3)]
- Returns:
The list of non-terminal states \(\mathcal{S}\)
- property states#
The list of all states including terminal ones, i.e. \(\mathcal{S}^+\) in (SB18). The terminal states are those where
is_terminal(state)is true.>>> from irlc.gridworld.gridworld_environments import FrozenLake >>> mdp = FrozenLake().mdp >>> mdp.states [(0, 1), (1, 2), (2, 1), (0, 0), (3, 1), (1, 1), (0, 3), (2, 0), (3, 0), (2, 3), 'Terminal state', (0, 2), (3, 3), (2, 2), (1, 0), (3, 2), (1, 3)]
- Returns:
The list all states \(\mathcal{S}^+\)
Solutions to selected exercises#
Solution to Sutton problem 3.14
The update is \(V(s) \leftarrow \sum_a \pi(a|s) \sum_{s', r} p(s', r |s, a) (r + \gamma V(s'))\). In our case the per-step reward is \(r=0\), \(\gamma = 0.9\) and the policy is uniform \(\pi(a | s) = \frac{1}{4}\). Reading of the four values of the value function surrounding the center square we get:
Solution to Sutton problem 4.1
According to the relationships we saw at the beginning of Todays lecture the action-value function satisfy:
Furthermore, when we take an action, we know what the next state \(s'\) is so the expectation disappear. We can now read of the value function from figure 4.1 and we get that in the first case \(q(11,down) = -1\) and in the second that \(q(7,down) = -1 + \gamma v_\pi(11) = -1 - 14\gamma = -15\).
Solution to Problem 2 (Bellmans equations)
Part a: Recall Bellmans equation (it does not matter which) says: \(v(s) = \mathbb{E}[R + \gamma v(s') \mid S_t = s]\). Therefore:
Solving we get that \(v_1 = \frac{1 + \gamma v_2}{2-\gamma} = 2\).
Part b: We already got the first equation from the previous problem. Applying a similar argument to the second equation leaves us with:
This can be written as a linear system of equations as:
Tip
During the exam, a few students correctly found the system of two equations (in my oppinion, the difficult part), but when they used Maple to re-write them as a linear system Maple obtained some very strange expressions probably due to the \(\gamma\) – when you use Maple to simplify or solve, try to check that you can re-produce the result by hand if you have time.
Bonus question: The inverse of \(A\) is \(A^{-1} = \begin{bmatrix} 2- \gamma & -\gamma \\ -\gamma & 2-\gamma \end{bmatrix}\) (use google!). Then find \(\mathbf{v}\) as
Problem 9.1-9.3
Problem 9.4: Policy evaluation
Problem 9.5: Policy iteration
Problem 9.6: Value iteration
Problem 9.8
Problem 9.9 - Gambler