AlignMNIST
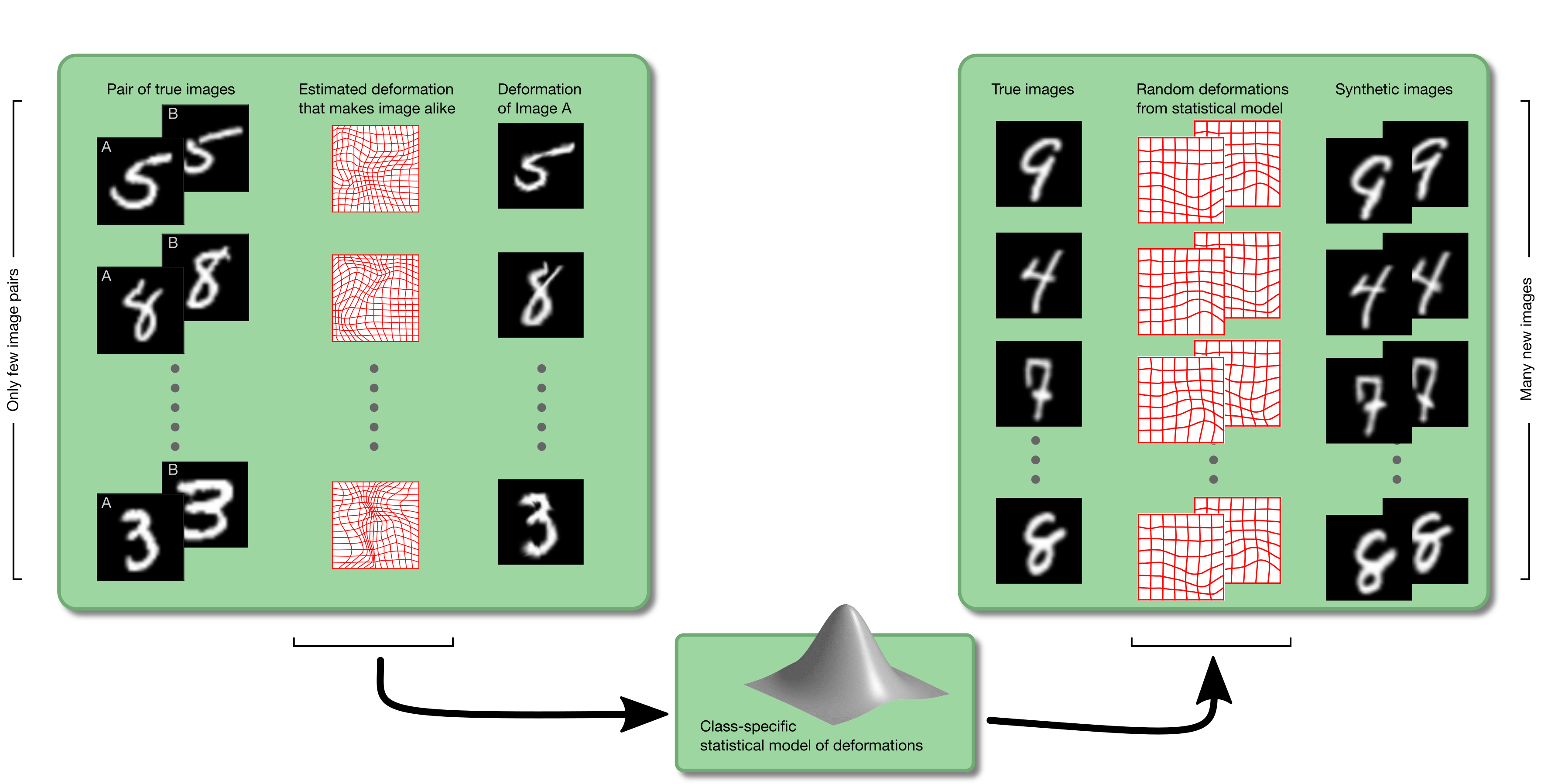
To learn a data augmentation scheme for the classic MNIST dataset, we pick pairs of images, aligns them under the assumption that the transformation is diffeomorphic, and finally build a statistical model of all estimated transformations. New data can then be generated by applying a randomly sampled transformation to a randomly chosen image. We do this on a per-class basis. The process is outlined in the figure (click to enlarge). This idea is strongly linked to that of congealing.
Relevant Publications
The process used to generate these datasets is explained in the paper Dreaming More Data: Class-dependent Distributions over Diffeomorphisms for Learned Data Augmentation. Please cite accordingly:
@inproceedings{hauberg:aistats:2016,
title = {Dreaming More Data: Class-dependent Distributions over Diffeomorphisms for Learned Data Augmentation},
author = {S{\o}ren Hauberg and Oren Freifeld and Anders Boesen Lindbo Larsen and John W. Fisher III and Lars Kai Hansen},
booktitle = {Proceedings of the 19th international Conference on Artificial Intelligence and Statistics (AISTATS)},
journal = {Journal of Machine Learning Research, W\&CP},
volume = {51},
pages = {342--350},
year = {2016}
}
The key building block in learning these deformations is the CPAB representation of diffeomorphisms. This is described in detail in the paper Highly-Expressive Spaces of Well-Behaved Transformations: Keeping It Simple. Again, it is helpful if you cite this paper when relevant.
@inproceedings{freifeld:iccv:2015,
title = {Highly-Expressive Spaces of Well-Behaved Transformations: Keeping It Simple},
author = {Oren Freifeld and S{\o}ren Hauberg and Kayhan Batmanghelich and John W. Fisher III},
booktitle = {International Conference on Computer Vision (ICCV)},
address = {Santiago, Chile},
month = Dec,
year = {2015}
}
The AlignMNIST and AlignMNIST500 datasets
Below you will find the AlignMNIST and AlignMNIST500 datasets. Currently, we make these available is numpy files. To read these in python you should do
import numpy as np
alignmnist = np.load('alignmnist.npz')
x = alignmnist['x']
y = alignmnist['y']
The first 60,000 images in AlignMNIST is the ordinary (non-deformed) MNIST training data. The next 60,000 images are random deformations applied to the MNIST data (kept in the same order). Likewise for the next 60,000 images, and so forth. This structure is useful when splitting the data into training and validation data.
If you have problems with the data, please contact Søren Hauberg
Principal deformations
To understand the deformations captured in the AlignMNIST dataset it can be useful to look at the principal deformations. The video below show these.